Rapid reinforcement learning with the hierarchy of policies that chase fleeing targets
Michał Bortkiewicz
supervisor: Tomasz Trzciński
Hierarchical division of control and sequential decision-making is unavoidable in large systems. In reinforcement learning, it is usually introduced with handcrafted subtasks to learn or with learned inflexible subgoals indicated within the original state space. In this paper, we reconsider assumptions that underlie those approaches and propose a new set of assumptions: 1) Goals of lower-level control are defined by projections returned by high-level controller, 2) higher-level control constantly verifies if lower-level goals are still valid, 2) if there is a better lower-level goal to pursue, our agent switches the target for lower policy even if the previous was not achieved. Consequently, we propose a novel hierarchical reinforcement learning algorithm that solves navigation tasks in dynamic environments based on these assumptions that lead to fast learning typical for hierarchical architectures. They also lead to smooth and dexterous control but above all, enable a fast reaction to unanticipated changes in the environment that exhibit dynamic situations for which the agent is not prepared. Also, lower-level policies considered within our approach are versatile enough to be useful in different tasks. This creates a natural framework for the transfer of knowledge in reinforcement learning.
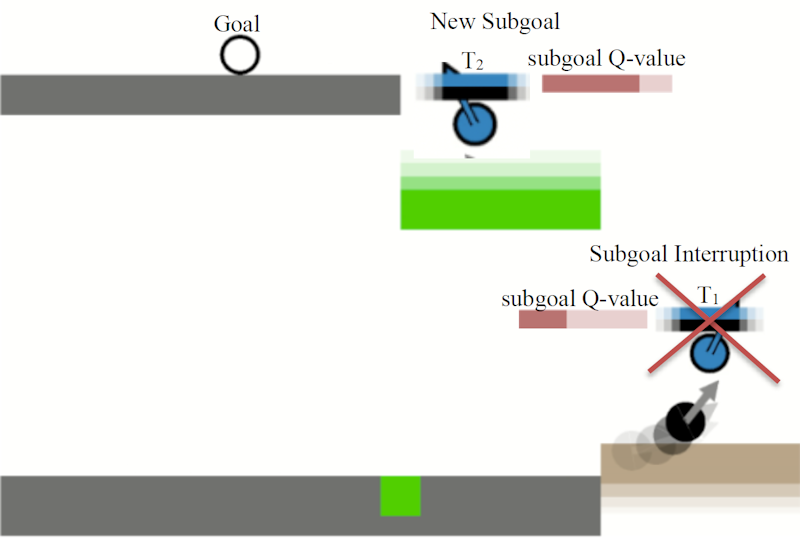
Fig. 1 Visualization of subgoal switching based on the subgoal Q-value. If the currently realized high-level action is suboptimal to the subgoal predicted in this moment, according to the Q-value, the agent switches the target it pursues.